Welcome to another thrilling edition of Leading Edge!
This week, we're diving deep into the enigmatic workings of OpenAI's latest marvel, O1. Imagine stepping into the mind of a machine that not only learns but reasons, adapts, and redefines what intelligence means in our digital age.
What makes O1 tick? And more importantly, why does it matter for the future of innovation, ethics, and our daily lives? Get ready to uncover the secrets behind this groundbreaking model and explore the ripple effects it’s poised to create across industries.
Fasten your seatbelts, because this is where the future begins!
The Dawn of True AI Reasoning
Something remarkable happened in the world of AI when OpenAI released O1. That wasn't immedaitely obvious to me at that time though (and many others - looking back at all those "meh" o1-preview reviews).
For the first time, a foundational model introduced "thinking before responding," a capability that would later be known as "inference time compute" or more populary "test-time compute."
The results? Extraordinary.
O1 didn't just pass benchmarks; it shattered them, achieving PhD-level performance across various academic disciplines. Three months later, OpenAI doubled down with O3, taking these capabilities to new heights. Enough for people to claim it's AGI (it isn't).
But how does it work? Why haven’t competitors like Google or Anthropic replicated it yet? And most importantly, what does this mean for the future of AI systems, both closed and open-source?
Let’s unpack it.
The Four Pillars of Advanced AI Reasoning
Building an AI system capable of reasoning at O1’s level isn’t just about scaling compute or training on more data.
According to the research paper, it’s about balancing four key components:
1. Policy Initialization - Teaching the basics
2. Reward Design - Creating the right incentives
3. Search - Helping the AI explore solutions
4. Learning - Allowing the AI to improve from experience
From Babbling to Brilliance: Policy Initialization
Imagine teaching a Rubik's cube to someone. You wouldn't start with advanced algorithms – you'd begin with basic concepts like what constitutes a "move" and what a solved cube looks like.
This is exactly how O1-like models begin their journey.
source: research paper - all green nodes are additional reserach papers
(note: each node here is an additional reserach paper - yes, the rabbit hole goes deep. You can visit the pdf listed at top for the links)
The process starts with pre-training, where the AI consumes vast amounts of internet text – like reading millions of books to understand grammar, facts, and basic reasoning patterns.
Then comes instruction fine-tuning, where the AI learns to follow human instructions and generate helpful responses - the difference between knowing facts and knowing how to use them effectively.
But what truly sets O1-style models apart is their "human-like reasoning behaviors."
These include:
Reward Design – Carrots, Sticks, and AI Learning
If you’ve ever trained a dog (or negotiated with a toddler), you know the power of rewards. The same principle applies to AI.
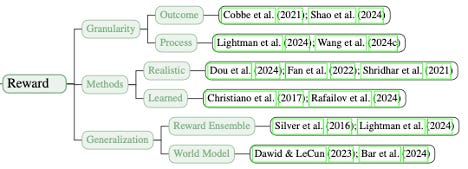
In O1, rewards come in two forms:
source: reserach paper
Outcome Rewards: Did the AI get the answer right?
Process Rewards: Did the AI follow a logical reasoning process, even if the final answer was wrong?
Designing these rewards is no easy feat. Too much emphasis on outcomes might encourage shortcuts, while focusing too heavily on the process could make the AI overly cautious.
To tackle these challenges, developers rely on techniques like:
Reward Shaping: Making reward signals clearer.
Preference Data: Comparing outputs to highlight “better” approaches.
Good reward design doesn’t just incentivize correctness—it nurtures a reasoning mindset.
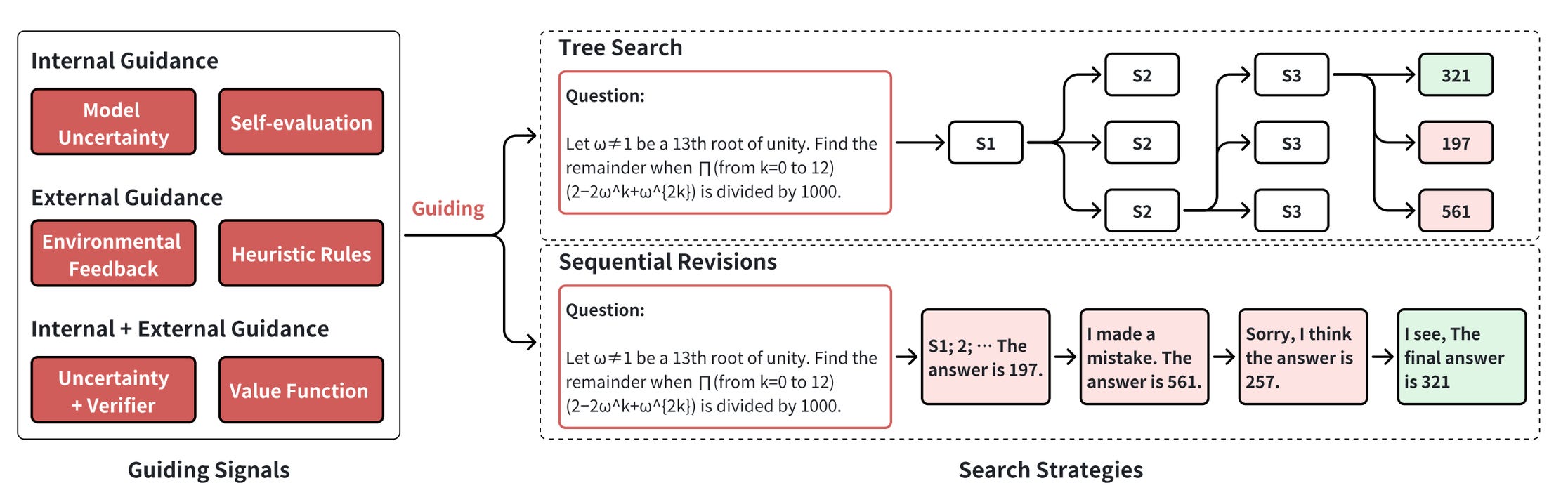
The Search for Solutions: How AI Explores Possibilities
Ever solve a puzzle and realize you needed to backtrack five moves ago? That’s Search in action.
source: research paper - all green nodes are additional reserach papers
For AI, search happens in two key phases:
Training-time Search: The AI explores reasoning paths during training, generating higher-quality learning data.
Inference-time Search: During real-time problem-solving, the AI evaluates multiple potential solutions before picking the best one.
Techniques like Tree Search and Sequential Revisions ensure that the AI isn’t just producing answers—it’s exploring pathways to better answers. This is one reason why O1 gets smarter with more time to “think.”
And just like humans, O1 benefits from not rushing through decisions. Previously, without O1, we used to manually simulate this process with GPT-4 like models by asking it to go through the output step by step.
Learning from Experience: The Final Piece of the Puzzle
source: research paper - all green nodes are additional reserach papers
The true magic happens when these systems learn from experience. Unlike traditional AI that follows fixed rules, O1-style models improve through interactions and feedback, using two main approaches:
1. Policy Gradient Methods:
The Open Source Revolution: What's Next?
DeepSeek v3 and its “DeepThink” capabilities gave us a glimpse of O1-like behavior in an open-source setting.
A New Dawn for AI Reasoning
For developers, businesses, and researchers, the implications are clear: the future isn’t just about building smarter AI—it’s about building AI that can think.
So, what do you think? Will open-source models like DeepSeek match O1’s reasoning capabilities? Is AGI on the horizon, or are we still several milestones away?
Drop your thoughts, share this with your network, and let’s keep the conversation going.